Compress and Evaluate Image Generation Models
Component |
Details |
|---|---|
Goal |
Demonstrate a standard workflow for optimizing and evaluating an image generation model |
Model |
|
Dataset |
|
Optimization Algorithms |
cacher(deepcache), compiler(torch_compile), quantizer(hqq_diffusers) |
Evaluation Metrics |
|
Getting Started
To install the dependencies, run the following command:
[ ]:
%pip install pruna
[ ]:
import torch
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
The device is set to the best available option to maximize the benefits of the optimization process.
1. Load the Model
Before optimizing the model, we first ensure that it loads correctly and fits into memory. For this example, we will use a lightweight image generation model, stabilityai/stable-diffusion-xl-base-1.0 but feel free to use any text-to-image model on Hugging Face.
Although Pruna works at least as good with much larger models, like FLUX or SD3.5, however, a small model is a good starting point to show the steps of the optimization process.
[ ]:
import torch
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained(
pretrained_model_name_or_path="stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.bfloat16,
)
pipe = pipe.to(device)
Now that we’ve loaded the pipeline, let’s examine some of the outputs it can generate. We use an example from this amazing prompt guide.
[ ]:
prompt = "Editorial Style Photo, Bonsai Apple Tree, Task Lighting, Inspiring and Sunset, Afternoon, Beautiful, 4k"
image = pipe(
prompt,
generator=torch.Generator().manual_seed(42),
)
image.images[0]
As we can see, the model is able to generate a beautiful image based on the provided input prompt.
2. Define the SmashConfig
Now that we’ve confirmed the model is functioning correctly, let’s proceed with the optimization process by defining the SmashConfig, which will be used later to optimize the model.
For diffusion models, the most important categories of optimization algorithms are cachers, compilers, and quantizers. Note that not all algorithms are compatible with every model. For Stable Diffusion models, the following options are available:
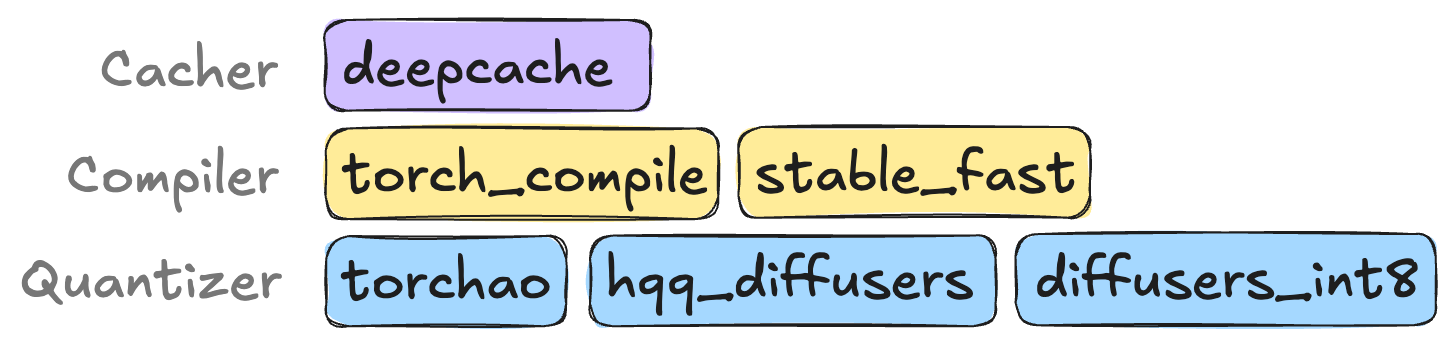
You can learn more about the various optimization algorithms and their hyperparameters in the Algorithms Overview section of the documentation.
In this optimization, we’ll combine deepcache, torch_compile, and hqq-diffusers. We’ll also update some of the parameters for these algorithms, setting hqq_diffusers_weight_bits to 4. This is just one of many possible configurations and is intended to serve as an example.
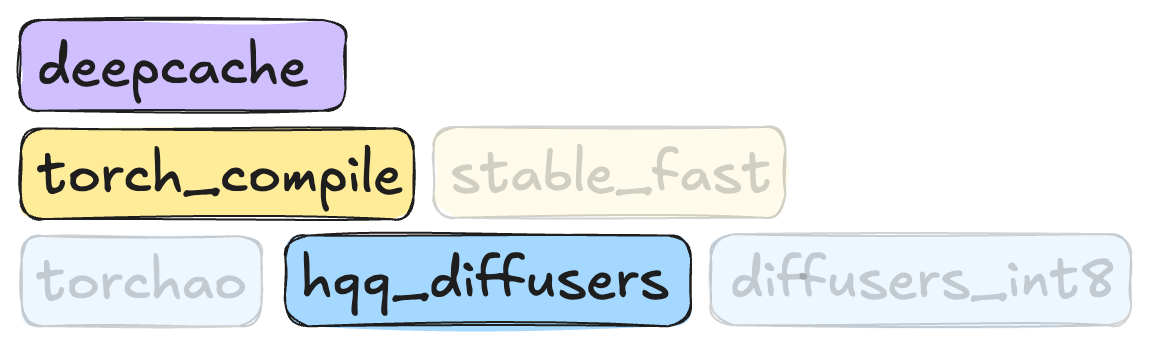
Let’s define the SmashConfig object.
[ ]:
from pruna import SmashConfig
smash_config = SmashConfig(device=device)
smash_config.add(
{"deepcache": {"interval": 2},
"torch_compile": {},
"hqq_diffusers": {"weight_bits": 4, "group_size": 64, "backend": "marlin"}
}
)
3. Smash the Model
Now that we’ve defined the SmashConfig object, we can proceed to smash the model. We’ll use the smash function, passing both the model and the smash_config as arguments. We make a deep copy of the model to avoid modifying the original model.
Let’s smash the model, which should take around 20 seconds for this configuration.
[ ]:
import copy
from pruna import smash
copy_pipe = copy.deepcopy(pipe).to("cpu")
smashed_pipe = smash(
model=pipe,
smash_config=smash_config,
)
Now that we’ve smashed the model, let’s verify that everything still works as expected by running inference with the smashed model.
If you are using torch_compile as your compiler, you can expect the first inference warmup to take a bit longer than the actual inference.
[ ]:
prompt = "Editorial Style Photo, Bonsai Apple Tree, Task Lighting, Inspiring and Sunset, Afternoon, Beautiful, 4k"
image = smashed_pipe(
prompt,
generator=torch.Generator().manual_seed(42),
)
image.images[0]
As we can see, the model is able to generate a similar image as the original model.
If you notice a significant difference, it might have several reasons, the model, the configuration, the hardware, etc. As optimization can be non-deterministic, we encourage you to retry the optimization process or try out different configurations and models to find the best fit for your use case but also feel free to reach out to us on Discord if you have any questions or feedback.
4. Evaluate the Smashed Model
Now that the model has been optimized, we can evaluate its performance using the EvaluationAgent. This evaluation will include metrics like elapsed_time for general performance and the clip_score for evaluating the quality of the generated images.
You can find a complete overview of all available metrics in our documentation.
[ ]:
from pruna import PrunaModel
from pruna.data.pruna_datamodule import PrunaDataModule
from pruna.evaluation.evaluation_agent import EvaluationAgent
from pruna.evaluation.metrics import (
LatencyMetric,
ThroughputMetric,
TorchMetricWrapper,
)
from pruna.evaluation.task import Task
# Define the metrics
metrics = [
LatencyMetric(n_iterations=20, n_warmup_iterations=5),
ThroughputMetric(n_iterations=20, n_warmup_iterations=5),
TorchMetricWrapper("clip_score"),
]
# Define the datamodule
datamodule = PrunaDataModule.from_string("LAION256")
datamodule.limit_datasets(10)
# Define the task and evaluation agent
task = Task(metrics, datamodule=datamodule, device=device)
eval_agent = EvaluationAgent(task)
# Evaluate base model and offload it to CPU
wrapped_pipe = PrunaModel(model=copy_pipe)
wrapped_pipe.move_to_device(device)
base_model_results = eval_agent.evaluate(wrapped_pipe)
wrapped_pipe.move_to_device("cpu")
# Evaluate smashed model and offload it to CPU
smashed_pipe.move_to_device(device)
smashed_model_results = eval_agent.evaluate(smashed_pipe)
smashed_pipe.move_to_device("cpu")
We can now review the evaluation results and compare the performance of the original model with the optimized version.
[ ]:
from IPython.display import Markdown, display # noqa
def make_comparison_table(base_model_results, smashed_model_results): # noqa
header = "| Metric | Base Model | Smashed Model | Improvement % |\n"
header += "|" + "-----|" * 4 + "\n"
rows = []
for base, smashed in zip(base_model_results, smashed_model_results):
base_result = base.result
smashed_result = smashed.result
if base.higher_is_better:
diff = ((smashed_result - base_result) / base_result) * 100
else:
diff = ((base_result - smashed_result) / base_result) * 100
row = f"| {base.name} | {base_result:.4f} {base.metric_units or ''}"
row += f"| {smashed_result:.4f} {smashed.metric_units or ''} | {diff:.2f}% |"
rows.append(row)
return header + "\n".join(rows)
display(Markdown(make_comparison_table(base_model_results, smashed_model_results)))
As we can see, the optimized model is approximately 2× faster and smaller than the base model. While the CLIP score remains nearly unchanged. This is expected, given the nature of the optimization process.
We can now save the optimized model to disk or share it with others:
[ ]:
# save the model to disk
smashed_pipe.save_pretrained("sdxl-smashed")
# after saving the model, you can load it with
# smashed_pipe = PrunaModel.from_pretrained("sdxl-smashed")
# save the model to HuggingFace
# smashed_pipe.push_to_hub("PrunaAI/sdxl-smashed")
# smashed_pipe = PrunaModel.from_pretrained("PrunaAI/sdxl-smashed")
Conclusion
In this tutorial, we demonstrated a standard workflow for optimizing and evaluating an image generation model using Pruna.
We defined our optimization strategy using the SmashConfig object and applied it to the model with the smash function. We then evaluated the performance of the optimized model using the EvaluationAgent, comparing key metrics such as elapsed_time and CLIP score.
To support the workflow, we also used the PrunaDataModule to load the dataset and the Task object to configure the task and link it to the evaluation process.
The results show that we can significantly improve runtime performance and reduce memory usage and energy consumption, while maintaining a high level of output quality. This makes it easy to explore trade-offs and iterate on configurations to find the best optimization strategy for your specific use case.