Automate finding the best SmashConfig with the Optimization Agent (Pro)
The OptimizationAgent is Pruna’s answer to efficient, intelligent model compression and deployment. This powerful tool is available in pruna_pro and automatically finds the best algorithm configuration for your model based on your specific objectives, requirements, and constraints.
The Optimization Agent offers two core capabilities: flexible optimization workflows and seamless integration with inference platforms.
Manual vs. Automated Smashing
Pruna allows you to compress your models in two different ways:
Manual Smashing
Manual mode gives you granular control. You handpick the compression algorithms and tune every hyperparameter. This approach is for expert ML engineers who know exactly what they want and need to squeeze out every drop of performance. The trade-off? You need deep technical knowledge, and you risk missing out on synergistic combinations unless you’re thorough.
Automated Smashing
Let the OptimizationAgent do the heavy lifting. Just load your base model, define your evaluation metrics, and launch the agent. It will:
Detect which compression techniques fit your model and hardware.
Search for the best combinations of algorithms.
Tune hyperparameters to hit your quality, speed, and memory goals.
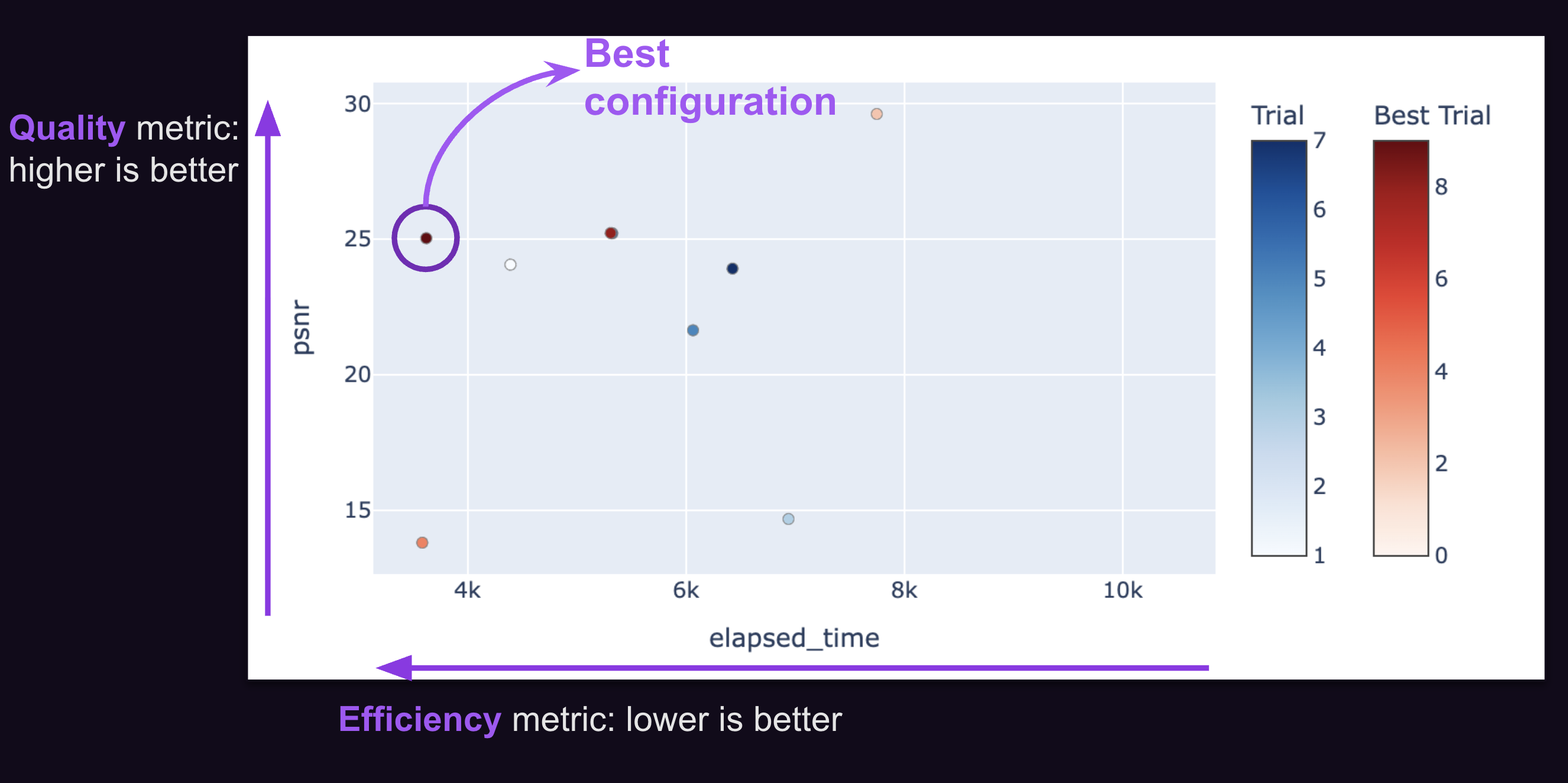
Once optimization is completed, you can visualize the results on a Pareto front plot to check the trade-offs and select the configuration that best fits your needs.
Note
Not using pruna_pro? Check out the optimization guide to learn how to optimize your model manually.
Basic Optimization Agent Workflow
pruna_pro follows a simple workflow for optimizing models:
graph LR
User -->|provides| C
User -->|provides| Task
User -->|provides| Metrics
C -->|input to| OptimizationAgent
Task -->|defines objective for| OptimizationAgent
Metrics -->|input to| Task
OptimizationAgent --> InstantSearch["Instant Search"]
OptimizationAgent --> ProbabilisticSearch["Probabilistic Search"]
InstantSearch -->|returns| PrunaModel
ProbabilisticSearch -->|returns| PrunaModel
User -->|optionally provides| B
subgraph A["Search Methods"]
InstantSearch
ProbabilisticSearch
end
subgraph B["Optional Enhancements"]
direction TB
Tokenizer
Processor
CalibrationData
end
C["PreTrained Model"]
B -->|informs| OptimizationAgent
style User fill:#bbf,stroke:#333,stroke-width:2px
style OptimizationAgent fill:#bbf,stroke:#333,stroke-width:2px
style C fill:#bbf,stroke:#333,stroke-width:2px
style Task fill:#bbf,stroke:#333,stroke-width:2px
style Metrics fill:#bbf,stroke:#333,stroke-width:2px
style PrunaModel fill:#bbf,stroke:#333,stroke-width:2px
style InstantSearch fill:#f9f,stroke:#333,stroke-width:2px
style ProbabilisticSearch fill:#f9f,stroke:#333,stroke-width:2px
style Tokenizer fill:#f9f,stroke:#333,stroke-width:2px
style CalibrationData fill:#f9f,stroke:#333,stroke-width:2px
style Processor fill:#f9f,stroke:#333,stroke-width:2px
Let’s see what that looks like in code.
from pruna_pro import OptimizationAgent
from pruna.evaluation.task import Task
from pruna.data.pruna_datamodule import PrunaDataModule
from diffusers import StableDiffusionPipeline
# Define your task with metrics and your model
model = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
task = Task(['latency'], datamodule=PrunaDataModule.from_string('LAION256'))
# Create the optimization agent with the model and your objectives
agent = OptimizationAgent(model=model, task=task)
# Find the best configuration instantly
optimized_model = agent.instant_search()
# Find the best configuration probabilistically
optimized_model = agent.probabilistic_search(
n_trials=15, # Number of configurations to try
n_iterations=15, # Iterations per evaluation
n_warmup_iterations=5, # Warmup iterations per evaluation of efficiency metrics
)
Select the Optimization Strategy
The OptimizationAgent offers two main strategies for finding the optimal configuration: instant search and probabilistic search.
Instant Search
The instant_search() method provides immediate suggestions based on predefined heuristics.
This method is best when you need:
Quick results without extensive search
Proven configurations for common model types
from pruna_pro import OptimizationAgent
from pruna.evaluation.task import Task
from pruna.data.pruna_datamodule import PrunaDataModule
from diffusers import StableDiffusionPipeline
# Define your task with metrics and your model
model = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
task = Task(['latency'], datamodule=PrunaDataModule.from_string('LAION256'))
# Create the optimization agent with the model and your objectives
agent = OptimizationAgent(model=model, task=task)
# Find the best configuration instantly
optimized_model = agent.instant_search()
Note
Currently, OptimizationAgent.instant_search() only supports a single efficiency objective at a time and does not take into consideration specific quality metrics.
Probabilistic Search
The probabilistic_search() method performs a custom search over the configuration space to directly optimize for your objectives defined as the Task.
This method is recommended when you need:
Optimal configurations (i.e. a combination of compression methods and their hyperparameters) for your specific use case
Balance between multiple objectives, e.g. latency and image generation quality
Thorough exploration of compression options to get the best result for your needs
from pruna_pro import OptimizationAgent
from pruna.evaluation.task import Task
from pruna.data.pruna_datamodule import PrunaDataModule
from diffusers import StableDiffusionPipeline
model = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
# define custom objective combination
task = Task(['latency', 'clip_score'], datamodule=PrunaDataModule.from_string('LAION256'))
agent = OptimizationAgent(model=model, task=task)
optimized_model = agent.probabilistic_search(
n_trials=15, # Number of configurations to try
n_iterations=15, # Iterations per evaluation
n_warmup_iterations=5, # Warmup iterations per evaluation of efficiency metrics
)
The runtime of probabilistic_search() is largely dominated by the evaluation of different configurations.
Make sure to choose a good balance between a thorough exploration and evaluation of the different configurations and a reasonable runtime.
INFO - Setting up search space for the OptimizationAgent...
INFO - Evaluating base model...
INFO - Base results:
INFO - clip_score: 27.8676700592041
INFO - latency: 3163.151220703125
INFO - Starting probabilistic search...
...
INFO - Trial 5 completed with results
INFO - clip_score: 26.025047302246094
INFO - latency: 291.9069315592448
Tested configuration:
SmashConfig(
'cacher': 'periodic',
'compiler': 'stable_fast',
'distiller': 'hyper',
'hyper_agressive': True,
'periodic_cache_interval': 4,
'periodic_start_step': 4,
)
INFO - --------------------------------
INFO - Trial 4 is on the pareto front with results:
INFO - clip_score: 28.641061782836914
INFO - latency: 3075.204524739583
INFO - Trial 2 is on the pareto front with results:
INFO - clip_score: 28.63214683532715
INFO - latency: 3043.8365397135417
INFO - Trial 3 is on the pareto front with results:
INFO - clip_score: 26.561687469482422
INFO - latency: 413.4533955891927
INFO - Trial 5 is on the pareto front with results:
INFO - clip_score: 26.025047302246094
INFO - latency: 291.9069315592448
INFO - --------------------------------
The OptimizationAgent will log a variety of information during the search, including:
Base Model Results: All given target metrics evaluated on the base model - this will be our baseline configuration for comparison.
Successful Trials: The OptimizationAgent will log the results of the successful trials, including the configuration used and the objective results.
Pareto Front: The OptimizationAgent will also log the current state of the Pareto Front, which is the set of configurations that are optimal for the given objectives.
Importantly, the first trial of the search will always be the base model. If the base model disappears from the Pareto Front over the course of the search, it means that a configuration has outperformed the base model across all objectives!
When the specified number of trials is reached, the search will stop and the “knee point” of the Pareto Front, signifying the best trade-off between the objectives, will be selected as the final configuration. Additionally, all configurations on the final Pareto Front will be saved so that you can select the best one manually if needed.
Configure the Optimization Agent
There are a few things you can configure to make the OptimizationAgent work for you.
Configure the Target Metrics
The OptimizationAgent will optimize for all metrics in the task by default.
You can also optionally specify target metrics to focus the search on a subset of the metrics defined in the Task:
from pruna_pro import OptimizationAgent
from pruna.evaluation.task import Task
from pruna.data.pruna_datamodule import PrunaDataModule
from diffusers import StableDiffusionPipeline
task = Task(['latency', 'clip_score'], datamodule=PrunaDataModule.from_string('LAION256'))
model = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
agent = OptimizationAgent(model=model, task=task)
# Set the target metrics
agent.set_target_metrics(['latency'])
optimized_model = agent.probabilistic_search(
n_trials=15, # Number of configurations to try
n_iterations=15, # Iterations per evaluation
n_warmup_iterations=5, # Warmup iterations per evaluation of efficiency metrics
)
INFO - Setting up search space for the OptimizationAgent...
INFO - Evaluating base model...
INFO - Base results:
INFO - clip_score: 27.8676700592041
INFO - latency: 7150.48515625
INFO - Starting probabilistic search...
...
INFO - Trial 5 completed with results:
INFO - clip_score: 28.49169921875
INFO - latency: 7980.82841796875
INFO - Tested configuration:
SmashConfig(
'quantizer': 'hqq_diffusers',
'hqq_diffusers_backend': 'bitblas',
'hqq_diffusers_group_size': 32,
'hqq_diffusers_weight_bits': 8,
)
INFO - --------------------------------
INFO - Trial 4 is on the pareto front with results:
INFO - latency: 5006.469954427083
INFO - Trial 11 is on the pareto front with results:
INFO - latency: 1092.8145833333333
INFO - Trial 10 is on the pareto front with results:
INFO - latency: 580.0285685221354
INFO - Trial 6 is on the pareto front with results:
INFO - latency: 519.7881591796875
INFO - --------------------------------
Configure Tokenizers, Processors or Calibration Data
The OptimizationAgent supports adding various components that might be needed for compression - make sure to specify as many as possible, as this will unlock more compression algorithms that can be taken into account.
from pruna_pro import OptimizationAgent
from pruna.evaluation.task import Task
from pruna.data.pruna_datamodule import PrunaDataModule
from transformers import AutoModelForCausalLM
# Set up model, task and agent
model_id = "facebook/opt-125m"
model = AutoModelForCausalLM.from_pretrained(model_id)
task = Task(['latency'], datamodule=PrunaDataModule.from_string("WikiText"))
agent = OptimizationAgent(model=model, task=task)
# Add a tokenizer if needed
agent.add_tokenizer(model_id)
# Add calibration data if needed
agent.add_data("WikiText")
# Find the best configuration instantly - now with an extended set of compatible compression algorithms
optimized_model = agent.instant_search()
Note
The data provided to the Task might differ from the data given to the OptimizationAgent in cases where you prefer to calibrate on a different dataset than the one used for evaluation.
Embed the Optimization Agent as an “Optimization Job”
Pruna’s OptimizationAgent plugs into inference engines (like AWS SageMaker) as an “Optimization Job.” Unlike standard deployment tools that only offer basic optimizations (FP8/FP16, quantization), Pruna combines multiple techniques for deeper efficiency gains.
You can expose optimization options via a simple UI, letting users:
Compare variants side-by-side.
Get recommendations based on hardware, budget, or use case.
Choose their preferred version before deployment.
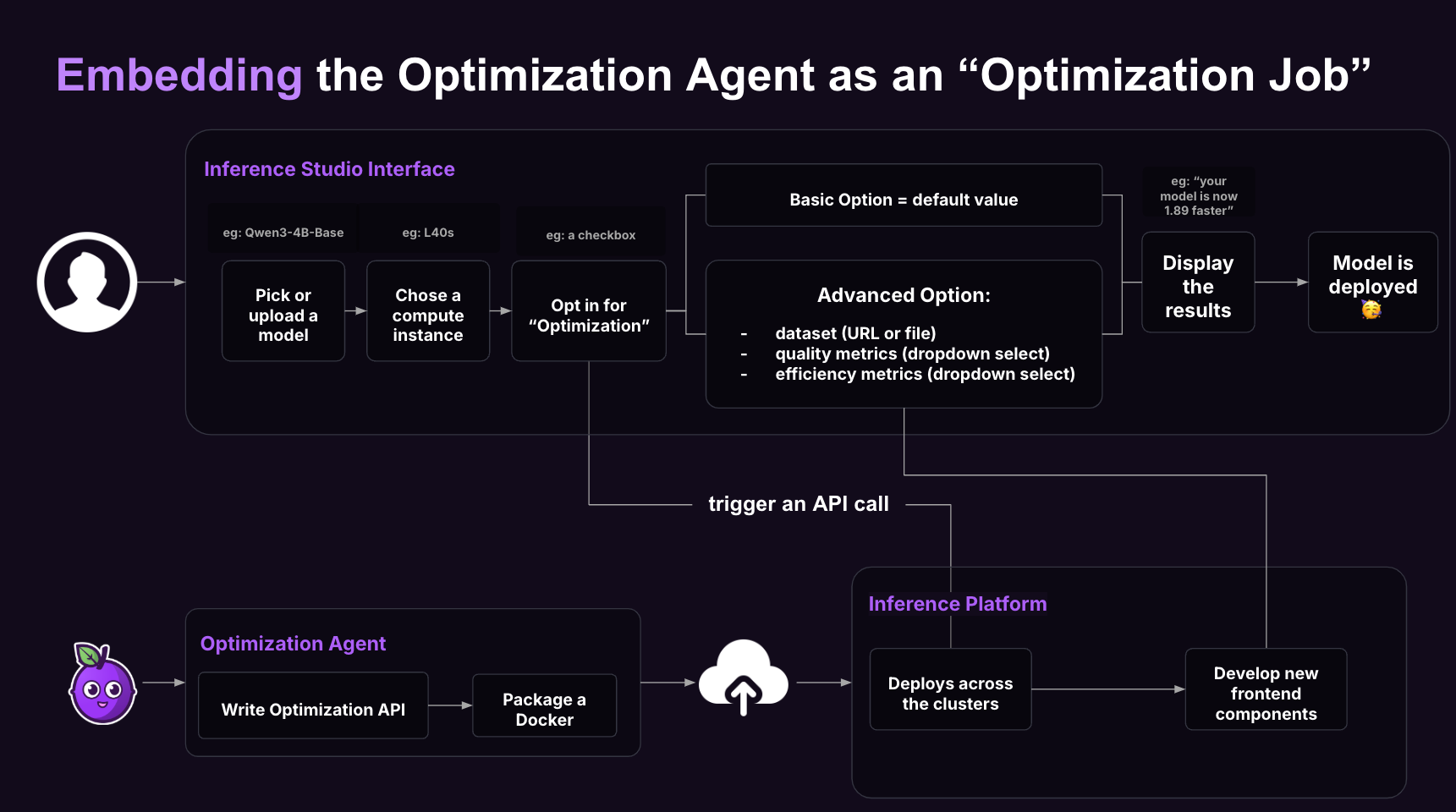
In short: The Optimization Agent automates, streamlines, and supercharges any model optimization and deployment, whether you want a push-button experience or advanced settings.
Best Practices
Define Clear Objectives
Use appropriate metrics in your task definition that represent your optimization goals well.
Provide Sufficient Trials
For probabilistic_search(), more trials generally lead to better results and more evaluation iteration give a more accurate estimate of the model performance.